Over the years at Rank Dynamics we have made considerable effort to “road test” our technology with real users whenever possible. The first opportunity came in 2008 when we studied how users with our browser extension selected results on Google. By using a result interleaving technique designed by Professor Thorsten Joachims to determine user preference between two competing ranking functions (i.e. our dynamically ranked results and Google’s native static results), we were able to demonstrate improvements in relevance of 30-40%. We packaged these results in a research paper which was eventually published by SIGIR.
Early this year, we had an opportunity to run a blind A/B test using eBay’s API. We drove people to an eBay search engine we created and populated with eBay’s products. Users were randomly and evenly split between control (with traditional static ranking as provided by the API) and treatment (with dynamic ranking as provided by our technology) groups. We did not dynamically generate indented recommendations, but we implemented infinite scroll and dynamically ranked all of the results after the first 10. While we believe dynamic ranking will work with smaller result sets, for the purpose of this test we restricted our data set to queries that returned at least 200 results, which represented about half of the total queries.
The data were impressive.
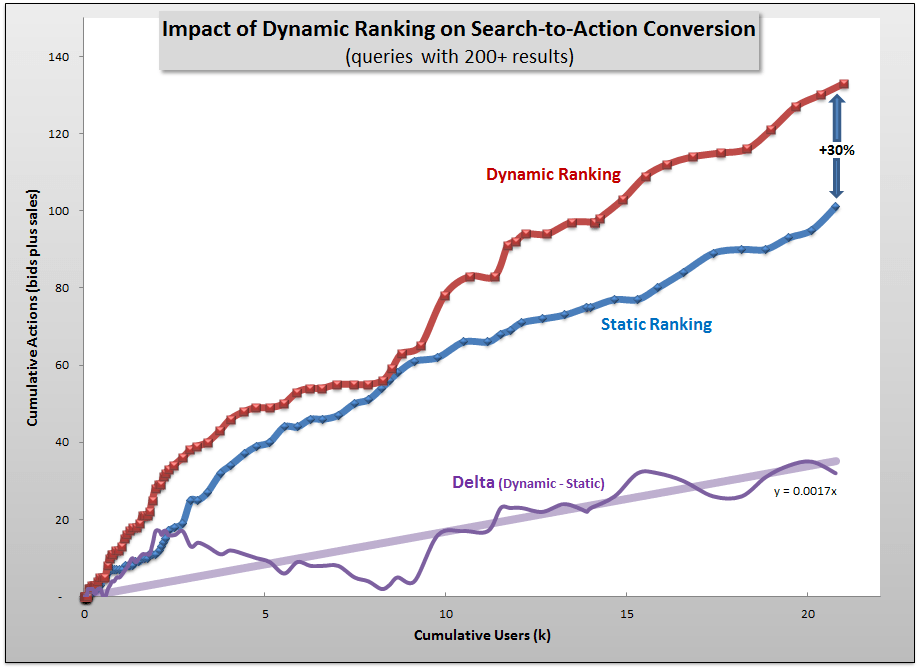
Each user on the x-axis above was a trial and the y-axis represents cumulative bids on auctions (a strong indication of intent to buy, even if the auction isn’t won) or purchases of products, collectively referring to as “actions.” The red and blue lines are, respectively, the dynamic and static groups while the purple line is simply the difference between the two.
Determining statistical significance with two binomial streams of data (each trial was considered a ‘success’ if the user completed one or more actions) was tricky. We employed Meeker’s Conditional Sequential Test for the Equality of Two Binomial Proportions. The null hypothesis was that there was no difference between the two proportions, or more simply that users in the dynamic and static groups would bid on auctions and purchase items at the same rate. After each trial (i.e. user) the test offers three possibilities:
- If the log probability ratio reaches the upper critical limit (i.e. “significant difference”) then reject the null hypothesis (i.e. conclude that the two groups are not equal) and terminate the test.
- If the log probability ratio reaches the lower critical limit (i.e. “no difference”) then accept the null hypothesis (i.e. conclude that there is no difference between the two groups) and terminate the test.
- If neither critical limit is reached, conduct another trial and continue the test.
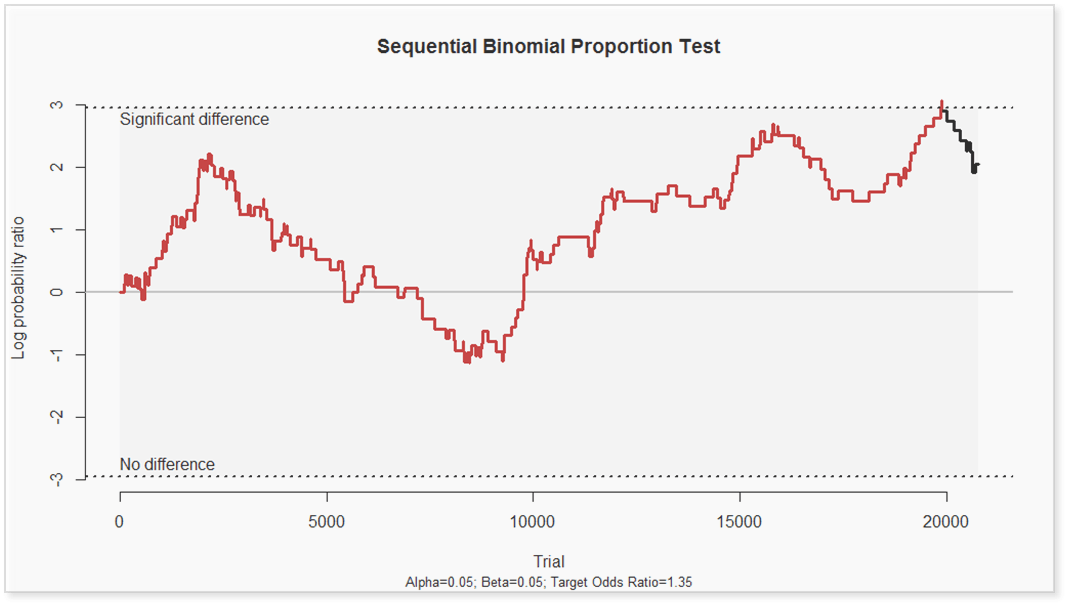
After 3 months and over 40,000 users (20,000 in each group), the SBPT (Sequential Binomial Proportion Test) produced a statistically significant result and we were able to reject the null hypothesis. In other words, using eBay’s product search, dynamically ranking results produced a statistically significant increase in the rate at which users bid on auctions or purchase items. Specifically, on a per user basis, we measured the following:
- +32% increase in sales
- +30% increase in bids plus sales
- +3.4% increase in clicks
- +8.2% increase in clicks after the top 10 results
Our work with Google’s results through our browser extension indicated that shopping was one category of search particularly amendable to dynamic ranking, which is confirmed by this eBay test. We will continue to put our technology through the ringer, but if queries on your shopping search produce hundreds of results, there is every reason to believe that dynamic ranking will work for you, too.