You may be forgiven for thinking that this post is the same as the previous, but as scientists are wont to do, we are conducting a 2nd experiment with eBay’s API in an attempt to replicate and confirm the impressive results from the 1st experiment.
This time, however, rather than randomly and evenly splitting users between control (i.e. traditional static ranking) and treatment (i.e. dynamic ranking) groups, we employed the result interleaving invented by Thorsten Joachims of Cornell University. This technique is now widely accepted in the search industry as a sound method for determining user preference between two competing ranking functions without explicit feedback. We used this same result interleaving in our 2009 SIGIR research paper which demonstrated dynamically ranked results delivering significant adaptivity gains over Google’s native static results.
One of the main advantages of result interleaving is that it eliminates bias when sampling. While 40,000 users went through the previous experiment, the fraction of those who actually bid on or purchased an item was very small (roughly 4.9 per thousand users in the control and 6.3 per thousand in the treatment). While a large enough sample size will diminish bias, a ‘prolific’ shopper randomly appearing in one group or the other could skew the results. The number of results clicked after the top 10 (roughly 100 per thousand users in the control and 108 per thousand users in the treatment) was thus less susceptible to bias because of the much higher incidences of ‘success’.
Nevertheless, the result interleaving in the 2nd experiment has the virtue of not splitting users which means that each group has an equal opportunity to receive clicks across all users and all queries in the experiment. Again, we did not dynamically generate indented recommendations, but we implemented infinite scroll and then interleaved static and dynamic results after the first 10. Also, while we believe dynamic ranking will work with smaller result sets, for the purpose of this experiment we restricted our data set to queries that returned at least 200 results, which represented about half of the total queries.
As before, the data were impressive.
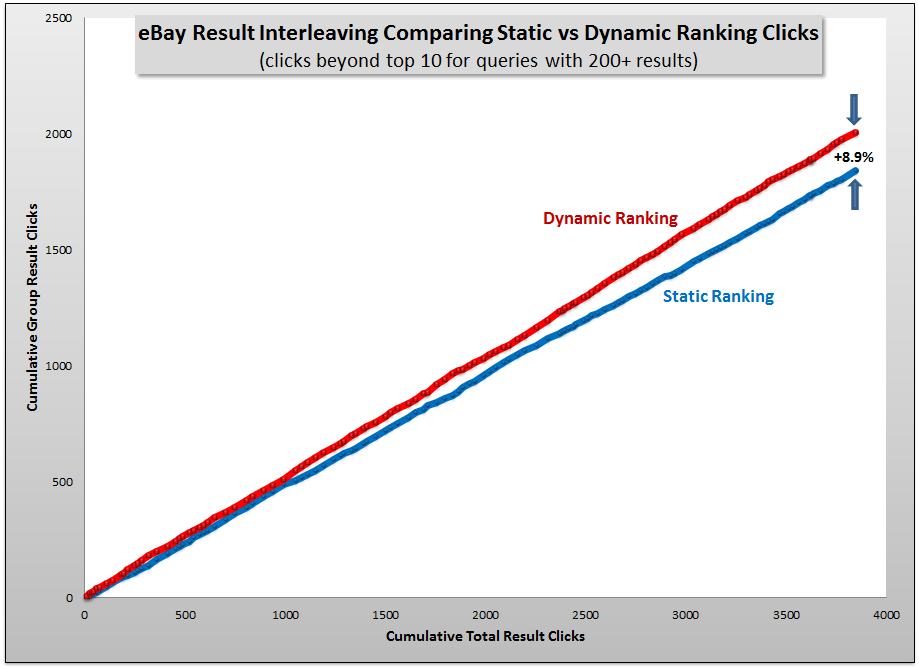
The x-axis is no longer users, but simply the cumulative number of results clicked beyond the top 10 in both the control (i.e. static) and treatment (i.e. dynamic) groups. The y-axis represents the cumulative number of results clicked in each of the respective groups, control and treatment. If our null hypothesis (that there is no difference in user preference between static or dynamic results) is true, then we would expect each group to receive half of the clicks and the two lines would be on top of each other. One can plainly see that this is not the case, but is the difference statistically significant?
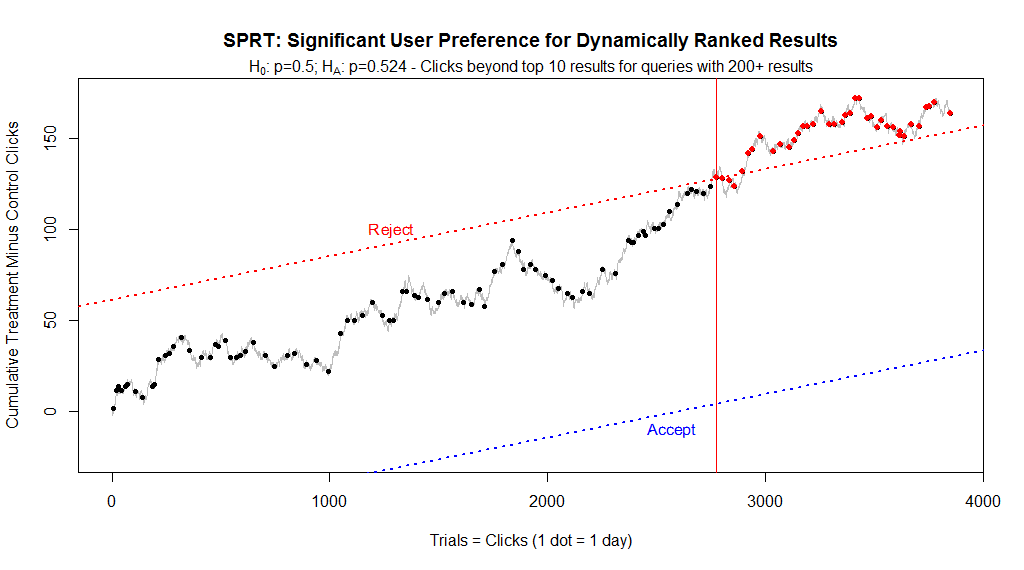
In the previous experiment we used the Meeker test for comparing the equality of two binomial proportions. For this experiment our task is simpler since we don’t have two binomial proportions but rather one (the success rate in the control is the inverse of that in the treatment, much like a coin flip.) Therefore we employ the standard Wald Sequential Probability Ratio Test using standard Type I and II errors with streaming data and a stopping rule, with upper and lower critical limits, similar to the Meeker test.
Even though we are continuing the test, after 3 months and almost 2800 clicks, the SPRT determined that we had a statistically significant outcome and we were once again able to eliminate the null hypothesis. In other words, after moving past the first 10 results, users demonstrated a clear and significant preference for dynamic ranking. After 4 months the improvement in the CTR of dynamically ranked results over statically ranked results was +8.9%, which is consistent with the +8.2% from the first experiment. (The increase in sales is currently at +32%, identical to the first eBay experiment, but it is not yet statistically significant, so we’ll update on that later.)
We will continue, as always, to push and test our technology as far as we can, but the evidence that users prefer dynamically ranked search results as opposed to traditional static results, by a wide margin, is considerable and mounting. If you would like to use dynamic ranking to boost your search performance, don’t hesitate to get in touch.
Over the years at Rank Dynamics we have made considerable effort to “road test” our technology with real users whenever possible. The first opportunity came in 2008 when we studied how users with our browser extension selected results on Google. By using a result interleaving technique designed by Professor Thorsten Joachims to determine user preference between two competing ranking functions (i.e. our dynamically ranked results and Google’s native static results), we were able to demonstrate improvements in relevance of 30-40%. We packaged these results in a research paper which was eventually published by SIGIR.
Early this year, we had an opportunity to run a blind A/B test using eBay’s API. We drove people to an eBay search engine we created and populated with eBay’s products. Users were randomly and evenly split between control (with traditional static ranking as provided by the API) and treatment (with dynamic ranking as provided by our technology) groups. We did not dynamically generate indented recommendations, but we implemented infinite scroll and dynamically ranked all of the results after the first 10. While we believe dynamic ranking will work with smaller result sets, for the purpose of this test we restricted our data set to queries that returned at least 200 results, which represented about half of the total queries.
The data were impressive.
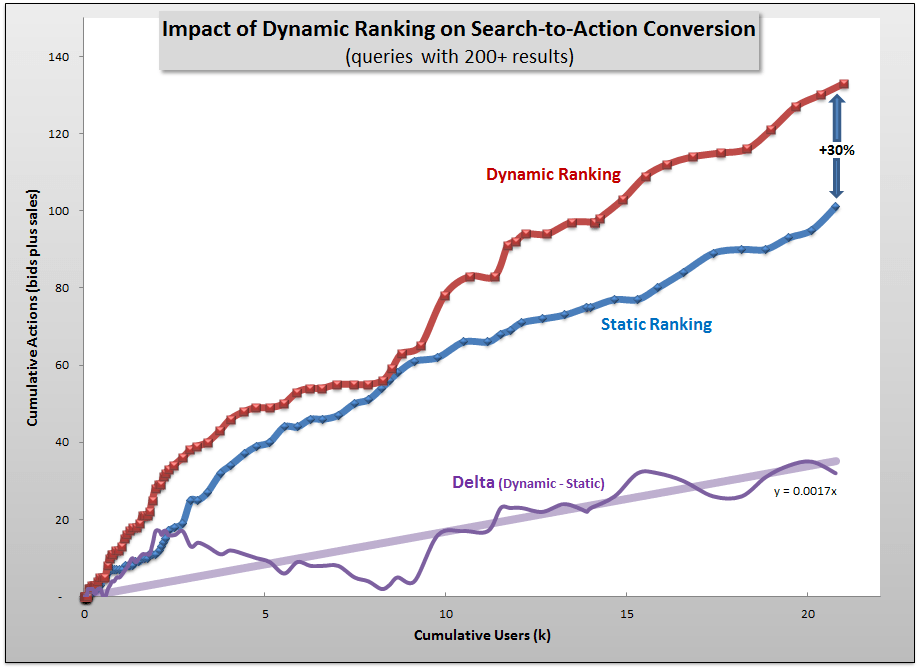
Each user on the x-axis above was a trial and the y-axis represents cumulative bids on auctions (a strong indication of intent to buy, even if the auction isn’t won) or purchases of products, collectively referring to as “actions.” The red and blue lines are, respectively, the dynamic and static groups while the purple line is simply the difference between the two.
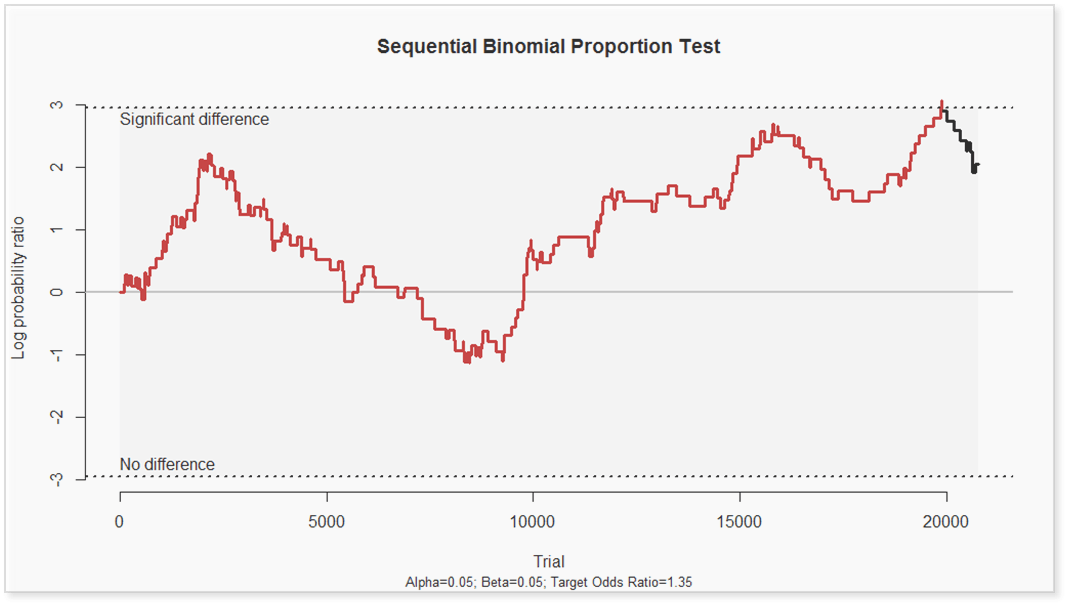
Determining statistical significance with two binomial streams of data (each trial was considered a ‘success’ if the user completed one or more actions) was tricky. We employed Meeker’s Conditional Sequential Test for the Equality of Two Binomial Proportions. The null hypothesis was that there was no difference between the two proportions, or more simply that users in the dynamic and static groups would bid on auctions and purchase items at the same rate. After each trial (i.e. user) the test offers three possibilities:
If the log probability ratio reaches the upper critical limit (i.e. “significant difference”) then reject the null hypothesis (i.e. conclude that the two groups are not equal) and terminate the test.
If the log probability ratio reaches the lower critical limit (i.e. “no difference”) then accept the null hypothesis (i.e. conclude that there is no difference between the two groups) and terminate the test.
If neither critical limit is reached, conduct another trial and continue the test.
After 3 months and over 40,000 users (20,000 in each group), the SBPT (Sequential Binomial Proportion Test) produced a statistically significant result and we were able to reject the null hypothesis. In other words, using eBay’s product search, dynamically ranking results produced a statistically significant increase in the rate at which users bid on auctions or purchase items. Specifically, on a per user basis, we measured the following:
+32% increase in sales
+30% increase in bids plus sales
+3.4% increase in clicks
+8.2% increase in clicks after the top 10 results
Our work with Google’s results through our browser extension indicated that shopping was one category of search particularly amendable to dynamic ranking, which is confirmed by this eBay test. We will continue to put our technology through the ringer, but if queries on your shopping search produce hundreds of results, there is every reason to believe that dynamic ranking will work for you, too.
The switch coincides with a shift in focus from consumer applications, specifically browser extensions, to enterprise software sales. The old brand will continue to exist for those individuals interested in adding a significant boost in relevance to their searches on Google, but our attention is now focused on providing a easy way for businesses to enhance their native search. Particularly, we are going to be looking at e-commerce search as here we have first order evidence of our ability to enhance revenue.
To all the users and business partners who have enabled us to create, develop and optimize our technology while delivering Dynamic Ranking for almost 7 billion queries, we say, “Thank you.” We are excited about this next chapter in our growth.
July 17th, 2012 was the last time we were able to successfully update our browser extension on AMO, Mozilla’s extension directory. That was version 3.4.3. Many things have obviously happened since then, including new features, bug fixes and optimizations. We’re therefore now happy to announce that Surf Canyon version 5.4.0, fully compatible with Firefox 35.0 and capable of being installed without having to restart the browser, was approved on January 14th.
What took so long?
Recently, Firefox has been undergoing a massive architectural change that would result in better security and performance for Firefox. “Electrolysis” (e10s) is a new, multi-process architecture coming in a future release of Firefox. This new architecture separates Firefox’s core from open websites. An unfortunate trade-off was that older add-ons weren’t guaranteed to be supported. Surf Canyon would no longer run on the newly envisioned Firefox; nor would some of our favorite add-ons, such as “Greasemonkey.”
While older add-ons weren’t supported, anything written using the Firefox AddOn SDK (formerly known as “Jetpack”) were to remain unaffected. In order to stay on Firefox, we rewrote the add-on using the Firefox AddOn SDK. Moving to a new add-on framework, however, meant learning new tricks. For example, Firefox’s AddOn SDK makes Ajax calls somewhat tricky, since only restricted parts of the add-on are able to access the Ajax APIs. We implemented a “Callback registry” to solve this problem. If you would like to see the code, we’ve posted it on Pastebin.
From the very beginning, Surf Canyon has been using the query “dolphins” as an illustration of how real-time contextualization can significantly enhance the user’s search experience. In the field of information retrieval this query is a classic example of ambiguity: is the user looking for the football team or the animal? Other queries like “bears” (again, football team or animal), “SVM” (support vector machine or Silvercorp Metals) and “java” (programming language, coffee or island) are a few other classic examples.
What’s nice about these classic examples, and why they are often used, is that it is easy to categorize results into one intent or another. While Surf Canyon’s real-time contextualization generally delivers the most user value with relatively homogeneous result sets, during demonstrations it is helpful to be able to easily “see” the effects, or lack thereof, of a particular ranking function on disambiguation.
Now, however, thanks to the Onion, we have a result for the query “dolphins” that could potentially span the two otherwise distinct and separate possible user intents: Florida Resort Allows Guests to Swim with the Miami Dolphins. Are users who select this result interested in the football team or the animal? Hard to say, although they are most certainly looking for a laugh.
Surf Canyon CEO Mark Cramer was honored to be interviewed by Robert Scoble on May 27th. While we always enjoy talking about how our technology dramatically improves the search experience, it is especially exciting to do so with such a renowned blogger and evangelist, who has a studio with three cameras. Here is a table of contents:
0m40s – Introduction with Apple ][ nostalgia.
1m40s – Elevator pitch.
5m50s – Live demonstration.
8m10s – Discussion of real-time contextualization for search.
9m20s – Why doesn’t Google do this? Hard to say given that it works so well.
10m55s – Speculation regarding impact on advertisements.
12m35s – Review of business.
13m23s – Mobile discussion.
15m50s – Review of funding.
16m10s – What’s next?
When doing something that has never been done before (as we do), it can be challenging to describe it using familiar terminology in a way that doesn’t create confusion while still conveying the newness of the idea. Large companies are sometimes capable of creating new terminology that is then adopted by others, but this can be particularly difficult for small entities. As such, for the sake of clarity, we describe how we have referred to our technology over the years and how we have now settled on “real-time contextualized search.”
When Surf Canyon launched its ground-breaking technology for dynamically re-ordering search results in response real time behavioral signals, we called our product a “Discovery Engine for Search“. The technology was referred to as “real-time implicit personalization” or simply “real-time personalization.” Unfortunately, this created a bit of confusion with some people in the search community:
The term “real-time” is an often abused and misunderstood. Technically “real-time computing” refers to guaranteeing a response “within strict time constraints.” More generally it is used to refer to a system that responds very quickly. “Quickly,” however, is subject to interpretation which is why we then sometimes referred to our technology as “instant” or “immediate personalization.”
Additionally, the term “personalization” may also lead to misunderstanding. In information retrieval “personalization” generally refers to collecting data about an individual over an extended period of time in order to generate models of that particular person’s long-term preferences in order to then use those models to modestly adjust relevance scores for future queries. Despite efforts to clarify the distinction with “real-time personalization” the term “personalization” can lead to premature interpretation.
The next year, a team of researchers at Cornell, lead by Professor Joachims, published a paper called “Dynamic Ranked Retrieval” which built upon our SIGIR research by running tests using labeled results to compute relevance metrics. The results were not real-world, but they were very impressive and their paper was selected as one of the six best at WSDM 2011. We found “dynamic ranked retrieval” to be more punchy than “real-time implicit relevance feedback.”
Nevertheless, while “dynamic ranked retrieval” has its appeal, a recent post in Search Engine Watch regarding Yahoo!’s interests in search offered this:
Contextual search works by algorithmically trying to determine what you really mean to search for, such as picking up cues from the immediate preceding searches, and presenting results based on that. [Emphasis added]
Algorithmically determining user intent by observing user interactions (“cues”) is what Surf Canyon has been doing since the very beginning. Our contextual search, however, is taken one large and very important step further – rather than waiting for subsequent searches in order to exploit user behavior signals, our technology immediately re-orders the result set in response to every user action that imparts additional understanding of the at-the-moment intent. As such, we henceforth declare that we develop Real-time Contextual Search.
Anyone familiar with Etsy knows that it is a fantastic website for finding handmade and vintage items, and a wonderful resource for gift-giving. Now, thanks to their search API and Rank Dynamics’s dynamic ranking technology, there is an improved, more conversational, way to search through the millions of items for sale on Etsy. Click over to the Rank Dynamics – Etsy Demo to try for yourself.
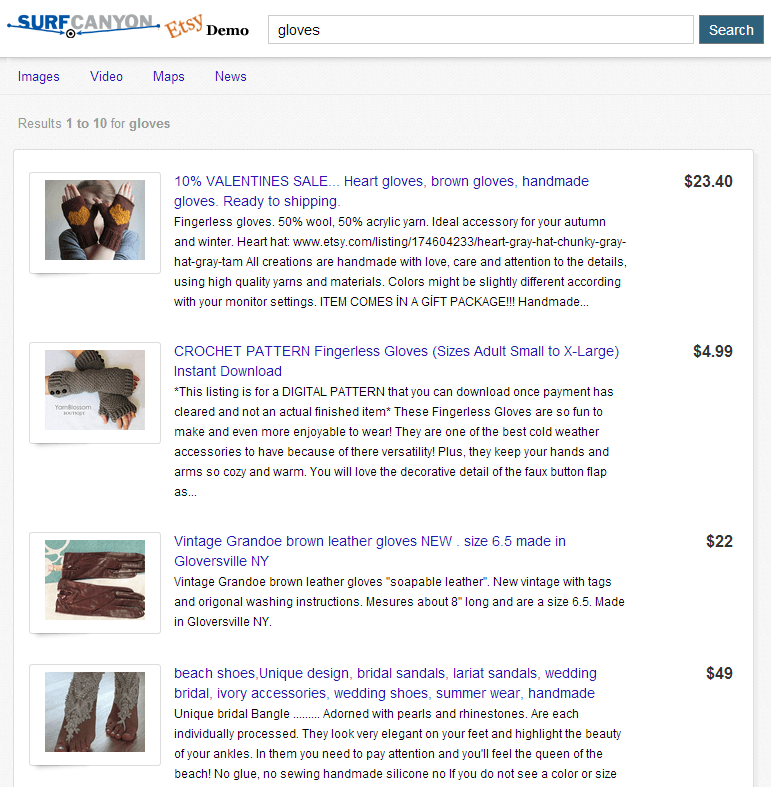
If you run a search for “gloves” on Etsy you’ll be presented with almost 70,000 results. There are facets on the left for drilling down, and of course users have the option of reformulating their queries to something more precise, but Rank Dynamics has always been about alleviating the cognitive load by automatically and immediately assisting users with finding what they need.
As such, a query for “gloves” on the Rank Dynamics – Etsy Demo will produce a page that looks like this:
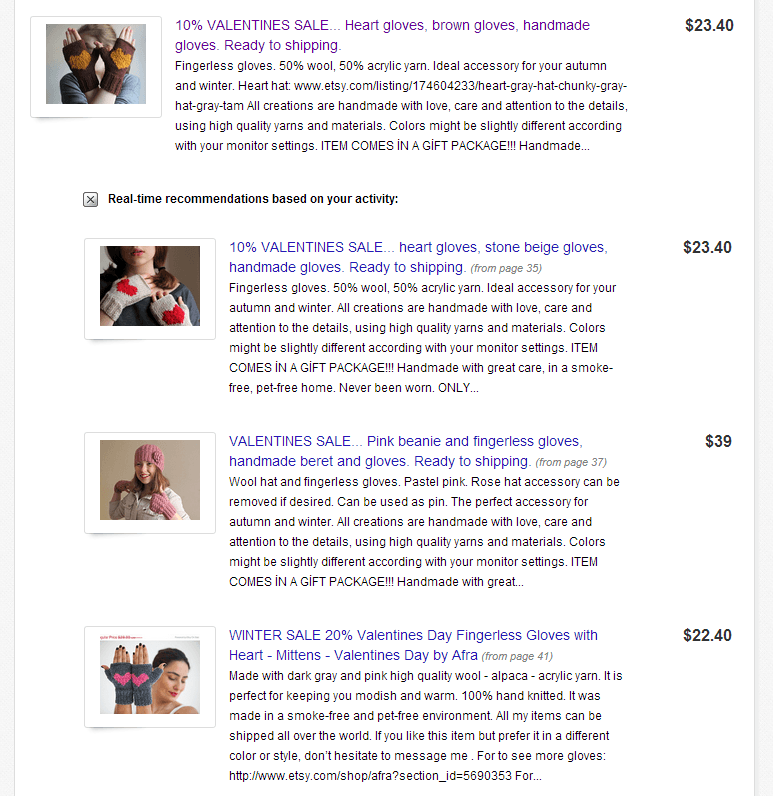
As it so happens, tomorrow is Valentine’s Day, so perhaps the very first result fancies you, and so you select it. If your shopping is done, congratulations. It’s very rare indeed to find something to purchases with only a single click! More likely, however, you’ll return to the search page to check out more, which is when you’ll helpfully be provided with real-time recommendations from Rank Dynamics’s dynamic ranking engine:
As you can see, these Valentine’s Day glove results are coming from pages 35, 37 and 41. It is hard to believe that anyone would ever dig that deep for a search result, but here they are helpful and automatically brought to page 1.
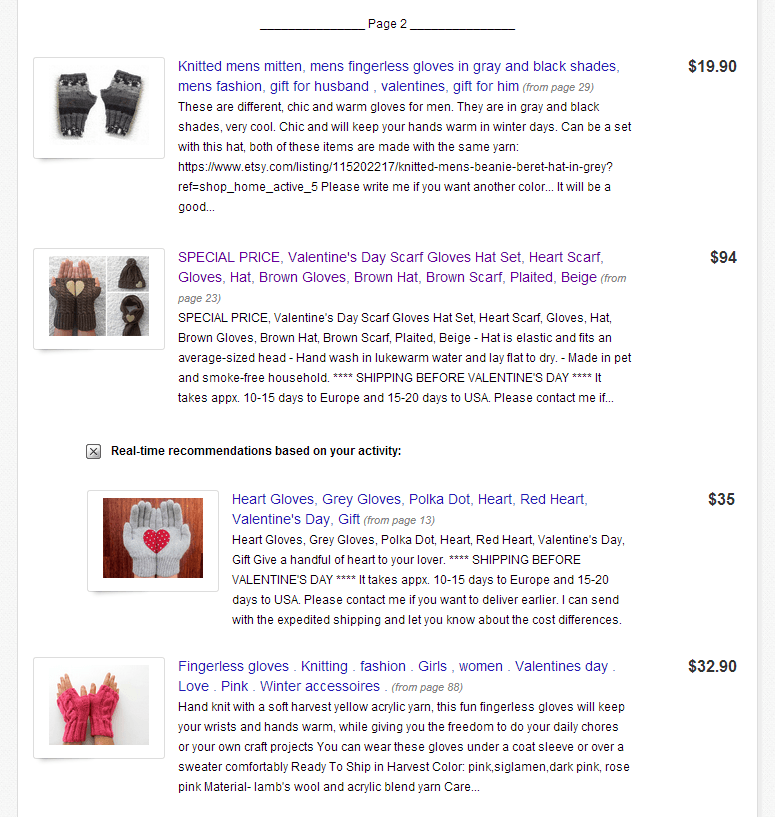
Every selection you make and every result you skip gives Rank Dynamics’s dynamic search engine more information about your information need, enabling a superior ranking every step of the way. Clicking “More Results” on page 1 will produce more re-ranked results on page 1. Moving over to page 2 will the produce a second page of results tailored in real time to your needs.
In this particular example, you get more of what you want – gloves for Valentine’s Day:
The results are coming from pages 29, 23 and, somewhat amazingly, 88. Clicking a result on page 2 produces yet more re-ranked results, presented as “recommendations,” and the process continues.
Rank Dynamics’s technology has been proven to deliver dramatic improvement in relevance, so give it a try!
The College Humor video below is NSFW, contains some profanity and mild sexual situations, but we’re posting it here because not only is it amusing, but it is an interesting insight into the relationship between users and search engines.
People struggle to find the “magic” set of keywords to describe their information need. As we first mentioned back in 2007:
In their paper entitled “Beyond the Commons: Investigating the Value of Personalizing Web Search,” Teevan et al. state that, “Web queries are very short, and it is unlikely that a two- or three-word query can unambiguously describe a user’s informational goal.”
Simply put, it can be difficult for the user to accurately express what he or she is looking for with just a few words. Even with many words, depending on the type of query, it can be difficult to express what is ultimately desired from the results, regardless of whether the user is an expert in the domain or not. How many times in real life, speaking with real people, do people need to employ many words, over many sentences, to express a thought or need?
As a result, people will often ultimately end up fumbling and guessing with their search engine, which is humorously displayed in the video below.
We also figured someone must have done this before, but after searching online the code that we found was much longer and a lot more complicated (mainly because it was trying to access parts of the Etsy API that required OAuth authentication) than what we had been expecting. However, just doing a product search doesn’t require any authentication, so we went ahead and wrote some much simpler code that did only what we needed.
The mission of Rank Dynamics is to transform search into a dynamic experience where fluid result pages respond to user actions in real time. We develop Dynamic Search, a real-time contextual search technology. By transforming static lists of links into dynamic search pages that automatically and immediately re-order results in response to user behavior signals, searchers are able to more quickly and easily find pertinent information that might otherwise have remained buried as deep as page 100.