You may be forgiven for thinking that this post is the same as the previous, but as scientists are wont to do, we are conducting a 2nd experiment with eBay’s API in an attempt to replicate and confirm the impressive results from the 1st experiment.
This time, however, rather than randomly and evenly splitting users between control (i.e. traditional static ranking) and treatment (i.e. dynamic ranking) groups, we employed the result interleaving invented by Thorsten Joachims of Cornell University. This technique is now widely accepted in the search industry as a sound method for determining user preference between two competing ranking functions without explicit feedback. We used this same result interleaving in our 2009 SIGIR research paper which demonstrated dynamically ranked results delivering significant adaptivity gains over Google’s native static results.
One of the main advantages of result interleaving is that it eliminates bias when sampling. While 40,000 users went through the previous experiment, the fraction of those who actually bid on or purchased an item was very small (roughly 4.9 per thousand users in the control and 6.3 per thousand in the treatment). While a large enough sample size will diminish bias, a ‘prolific’ shopper randomly appearing in one group or the other could skew the results. The number of results clicked after the top 10 (roughly 100 per thousand users in the control and 108 per thousand users in the treatment) was thus less susceptible to bias because of the much higher incidences of ‘success’.
Nevertheless, the result interleaving in the 2nd experiment has the virtue of not splitting users which means that each group has an equal opportunity to receive clicks across all users and all queries in the experiment. Again, we did not dynamically generate indented recommendations, but we implemented infinite scroll and then interleaved static and dynamic results after the first 10. Also, while we believe dynamic ranking will work with smaller result sets, for the purpose of this experiment we restricted our data set to queries that returned at least 200 results, which represented about half of the total queries.
As before, the data were impressive.
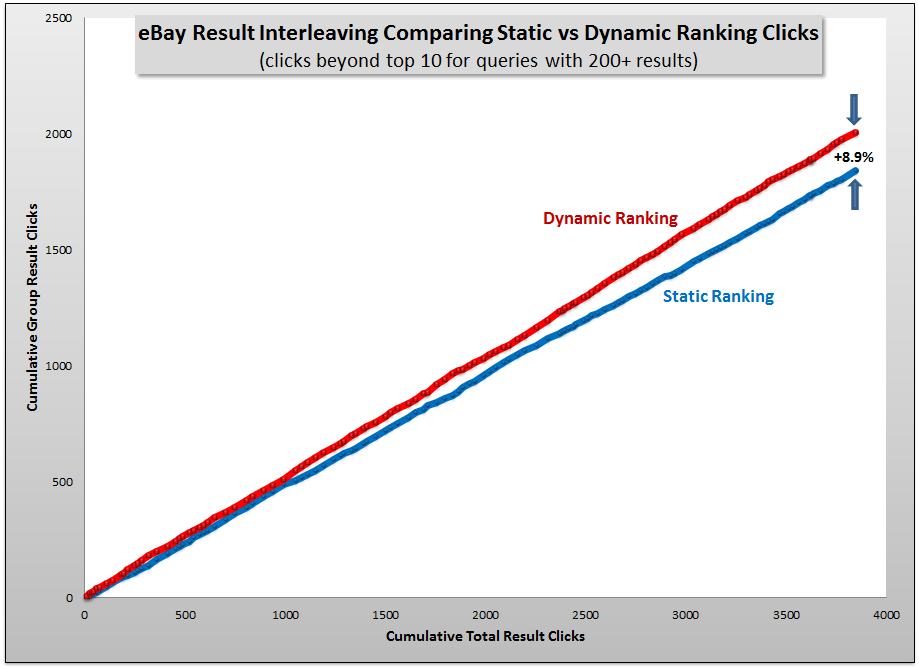
The x-axis is no longer users, but simply the cumulative number of results clicked beyond the top 10 in both the control (i.e. static) and treatment (i.e. dynamic) groups. The y-axis represents the cumulative number of results clicked in each of the respective groups, control and treatment. If our null hypothesis (that there is no difference in user preference between static or dynamic results) is true, then we would expect each group to receive half of the clicks and the two lines would be on top of each other. One can plainly see that this is not the case, but is the difference statistically significant?
In the previous experiment we used the Meeker test for comparing the equality of two binomial proportions. For this experiment our task is simpler since we don’t have two binomial proportions but rather one (the success rate in the control is the inverse of that in the treatment, much like a coin flip.) Therefore we employ the standard Wald Sequential Probability Ratio Test using standard Type I and II errors with streaming data and a stopping rule, with upper and lower critical limits, similar to the Meeker test.
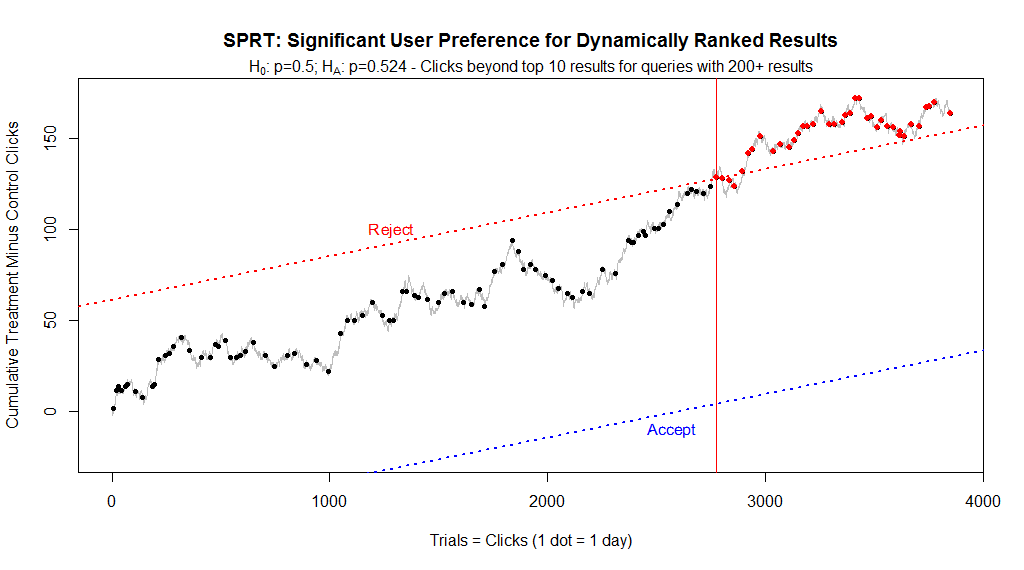
Even though we are continuing the test, after 3 months and almost 2800 clicks, the SPRT determined that we had a statistically significant outcome and we were once again able to eliminate the null hypothesis. In other words, after moving past the first 10 results, users demonstrated a clear and significant preference for dynamic ranking. After 4 months the improvement in the CTR of dynamically ranked results over statically ranked results was +8.9%, which is consistent with the +8.2% from the first experiment. (The increase in sales is currently at +32%, identical to the first eBay experiment, but it is not yet statistically significant, so we’ll update on that later.)
We will continue, as always, to push and test our technology as far as we can, but the evidence that users prefer dynamically ranked search results as opposed to traditional static results, by a wide margin, is considerable and mounting. If you would like to use dynamic ranking to boost your search performance, don’t hesitate to get in touch.